original 数据通过一系列数据代理的处理、分割、读取、传输,有这么多环节(如果采用多级代理,中间环节会更多),最后放到hdfs个人认为在数据的量比较少(几百,几十g)的时候,脚本自己提交给hdfs就已经相当不错了,并没有体现出所谓的分布式日志收集的优势。当数据的量急剧上升T级或更高时,可能反映flumeng。
自6、 flume拦截器是什么设计模式
learning flume以来,实现了多源日志的自动提取和多目标的自动传输,但数据 清洗的进程一直是在hadoop中用MR程序清洗进行的。有没有办法直接在flume中编程匹配相关的数据数据,过滤掉不标准的脏数据,所以决定打这个/。从拦截正文开始,定制拦截器编程,完成每个正文字符串解析字段的规则提取和拼接。我们定制的类叫做LogAnalysis如下:packagecom。besttone.interceptorimport com . Google . common . base . charsets;import com . Google . common . collect . lists;import org . Apache . commons . lang . string utils;importorg.apache. flume。语境;importorg.apache. flume。事件;。
7、Flume快速入门Flume是一个开源的日志系统。它是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据 senders,用于收集数据;同时,FLume提供了简单处理数据和编写各种数据接收器(可自定义)的能力。FLume是一个流日志收集工具。Flume提供了简单处理数据并写入各种数据接收者(可定制)的能力。Flume提供了从本地文件(spoolingdirectorysource)、实时日志(taildir、exec)、REST消息、Thift、Avro等下载的能力。
代理是水槽分布式系统中的核心角色,水槽采集系统由代理连接。每个代理相当于一个数据deliver,里面有三个组成部分:把数据从信源到信道再到信宿的传递形式是一个事件;事件Event是一个数据流单元。Flume基础设施:Flume可以直接从单个节点收集数据,主要用于集群数据。
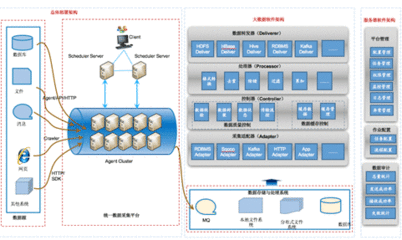
-2/的收款是大数据业务处理中非常重要的一步。很多公司的平台每天都会产生大量的日志(一般是streaming 数据,比如搜索引擎的pv和查询),处理这些日志需要特定的日志系统。一般来说,这些系统需要具备以下特点:Flume是Cloudera公司开发的高可用、高可靠的分布式海量日志收集、聚合和传输系统,于2009年捐赠给。
因为数据的来源是可定制的,所以Flume可以用来传输大量的事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息以及几乎任何可能的。类似Flume的开源框架有脸书的Scribe、Apache的Chukwa、阿里巴巴的TimeTunnel等,Flume中有一个或多个代理。对于每个代理,它都是一个独立的守护进程(JVM),它从客户端或其他代理接收集合,然后将获得的数据快速传输到下一个目的节点sink或代理。







