我想问一下哪些并行数据库分为分布式并行数据库和集群式并行数据库,是建立在MPP和集群式并行计算环境基础上的数据库系统。并行数据挖掘的并行性是什么意思?并行数据挖掘技术不同于其他并行算法,它需要处理大规模的数据,通常有三种并行数据挖掘策略:1 .幼稚并行,也就是人们通常所说的网络并行。

Oracle的数据库日志称为redolog,记录所有的数据变化。重做日志可用于修复损坏的数据库。重做日志是用于恢复的重要数据,也是一项高级功能。重做条目包含由相应操作引起的数据库更改的所有信息。所有重做条目最终都将被写入重做文件。Redologbuffer是为了避免重做文件的IO引导。由于性能瓶颈,在sga中分配的内存块,重做条目首先位于用户内存(PGA)中。为了避免冲突,LGWRbuffer由redo本地化闩锁保护,每个服务进程都需要获得闩锁才能分配redobuffer,因此处于高并发、数据修改频繁的ol中。在tp系统中,我们通常可以观察到redoallocationlatch等待重做写入redobuffer的全过程如下:在PGA中产生RedoEnrey >服务进程获取RedoCopylatch(有多个CPU_COUNT。

本文来自本教程,我们将学习如何使用多个GPU:数据并行的用法。用PyTorch来使用GPU是非常容易的。可以把模型放到GPU上:注意调用my_tensor.to(device)会在GPU上返回my_tensor的新副本,而不是重写my_tensor。你需要把它赋给一个新的张量,在GPU上使用。

但是,PYTORCH默认只使用一个GPU。通过使用DataParallel使模型并行运行,您可以轻松地在多个GPU上运行您的操作:这是本教程的核心。我们将在下面更详细地讨论它。导入和参数导入PyTorch模块并定义参数设备虚拟数据集创建一个虚拟(随机生成)数据集。你只需要实现Python的神奇函数getitem: simple model。为了演示,我们的模型只获得一个输入,执行一个线性操作并给出一个输出。
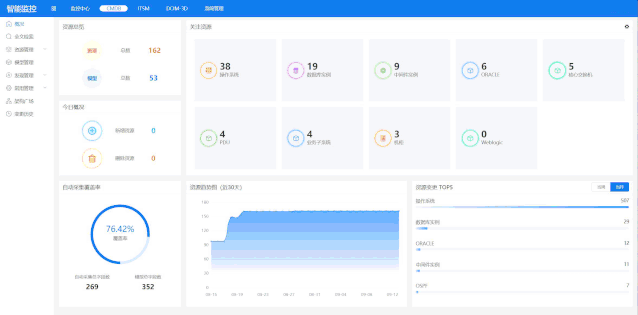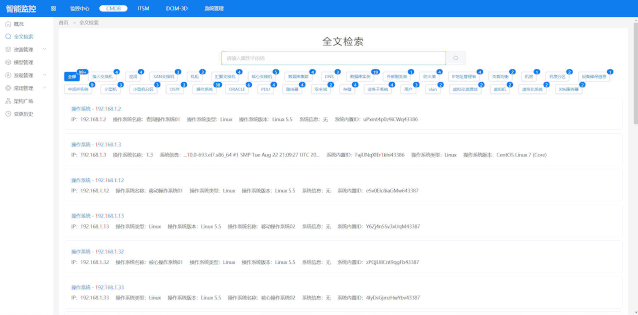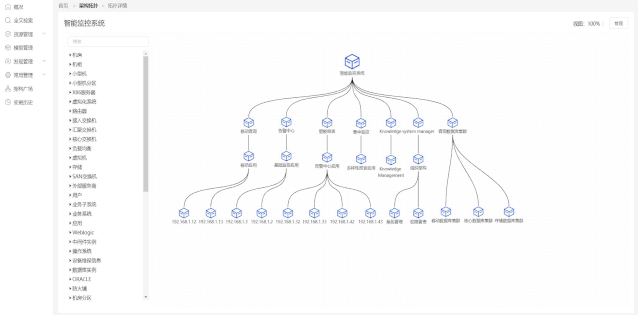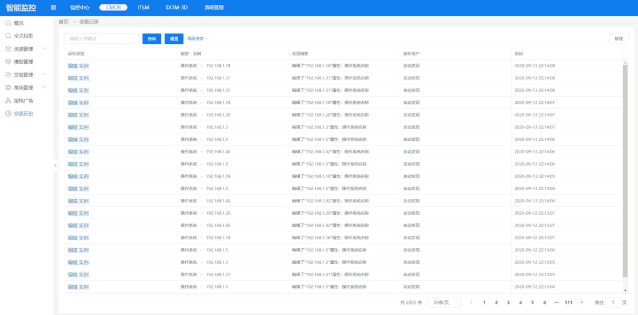
根据php手册中对fetch_assoc函数的描述:mysqli _ fetch _ assocfetchresultsrowasanaassociative array,该函数的作用是从数据库查询的结果集中取一条(行)记录,作为关联数组返回。如果想要显示结果集中的所有数据,首先,可以使用fetch_all函数。
3、为什么Java程序在并发的情况下数据库会出现重复记录在数据表中建立唯一性约束,在程序中选择覆盖或忽略。这是一个高并发多线程的问题。例如,如果数据粒度不是为行级锁设计的,则记录A是100。在并发的情况下,两个人得到记录A,更新70,更新80,实际上拿走了50,但是因为并发,数据不正确。
4、想问并行数据库有哪些并行数据库分为分布式并行数据库和集群式并行数据库,是基于MPP和集群式并行计算环境的数据库系统。并行数据库系统是新一代高性能数据库系统。并行数据库系统的目标是高性能和高可用性。通过多个处理节点并行执行数据库任务,可以提高整个数据库系统的性能和可用性。
5、串行器怎么把并行数据合成串行数据用同轴线输出的1。将输入信号A、B、C和D连接到四个输入端口。2.根据预定协议(如RS232协议)设置输出时钟信号和数据格式等参数。3.将时钟信号连接到串行器的时钟输入端口。4.串行器开始工作,它会根据时钟信号的频率从输入端口读取数据。5.在每个时钟周期,串行器将四个输入数字的状态打包成一个字节,然后将该字节发送到输出端口。发送顺序可以是从左到右,也可以是从右到左,具体顺序取决于协议。
6、并行数据挖掘是指什么并行呢?并行数据挖掘技术不同于其他并行算法,它需要处理大量的数据。众所周知,对于并行性来说,交互之间的消耗(即内存的使用)是一个比执行时间(计算阶段)重要得多的因素。串行的数据挖掘算法对于小规模的数据也需要大量的运行时间,可供分析的数据增长很快,因此需要寻找并行的数据挖掘算法。目前,并行数据挖掘算法已经得到了充分的研究。算法的复杂度可以从两个方面来表达:空间复杂度和时间复杂度。
从算法树的结构来看,通常的串行算法树是“深而窄”的;并行算法树的结构大不相同。为了达到将时间复杂度转化为空间复杂度的目的,并行算法树采用了“浅而宽”的结构,即每一时刻所能容纳的计算量相应增加,从而尽可能减少整个算法的步骤。通常有三种并行数据挖掘策略:1 .幼稚并行,也就是人们通常所说的网络并行。网络并行就是通过高速的信息网络,充分利用互联网上的计算机资源,实现对大规模数据的并行计算。
7、数据与模型并行利用计算机集群,让机器学习算法更好地从大数据中训练出性能优异的大模型,是分布式机器学习的目标。为了实现这一目标,一般需要根据硬件资源和数据/模型规模的匹配情况,划分计算任务、训练数据和模型,分布存储和训练。分布式机器学习可分为计算并行模式、数据并行模式和模型并行模式。假设系统中的工作节点有共享内存(如单机多线程环境),可以存储数据和模型,每个工作节点对数据有完全的访问权和读写权。
我们称这种并行模式为计算并行模式。见书上的公式,P119数据样本划分和数据维度划分是两种常用的数据划分方法。其中,样本划分有随机采样和(全局/局部)置乱分割方法,一般来说,划分数据时要考虑以下两个因素。一个是数据量和数据维数相对于本地内存的大小,以此来判断样本划分和维数划分后,数据是否能恰当地存储在本地内存中,另一个是优化方法的特性。







